
Last week I was "attending" NAACL 2021 online, one of the top conferences in NLP. Although the number is small, there were some papers that are related to Education×NLP, which I'm going to summarize below in this post. I might be missing some other important papers—let me know!
Quality estimation for grammatical error correction
Grammatical error correction, or GEC, is a task to automatically correct grammatical errors in the input text (think of Grammarly) often written by language learners. It has a long tradition in NLP and one of the most extensively studied AI×Education subfields.
Since the advent of sequence-to-sequence (seq2seq) models (Sutskever et al. 2014), neural seq2seq models became a de-facto choice for solving the GEC task. This is equivalent to considering input texts that may contain grammatical errors as one language, and the output texts that are error-free as another, effectively rendering GEC a machine translation task.
One issue with GEC and machine translation in general is that you are never sure if the output is correct or not. Neural machine translation systems are notorious for producing output that is natural but obviously wrong. One way to detect this is quality estimation (See Specia et al. 2018 for a good summary of this field), whose goal is to predict how good the produced translation is based on the input and the output, without referring to the gold standard answer. GEC effectively being an MT task, a similar technique may be useful for improving the quality of grammar correction as well.
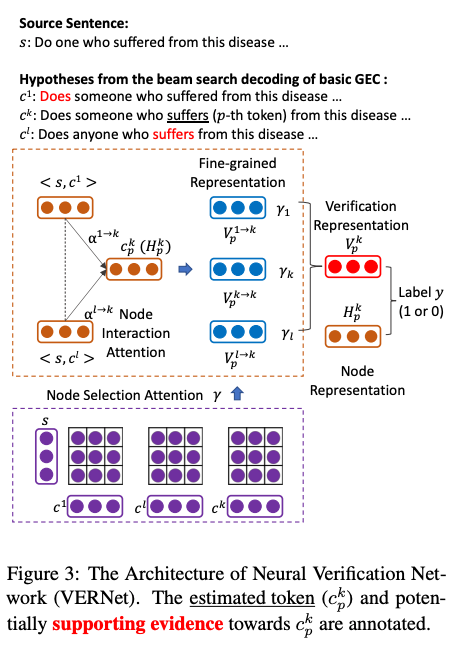
Quality estimation for GEC was already explored by Chollampatt and Ng, 2018, and this paper by Liu et al. proposes an improved version of a QE algorithm that takes multiple hypotheses (correction candidates generated by beam search) into account. The core of their method, which is inspired by multi-hypotheses MT evaluation (Fomicheva et al. 2020), is a network (a graph) of hypotheses where each token in a (source, hypothesis) pair attends to others in another node, and the final nodes are obtained by aggregating those representations.
There are two types of supervision for this model. One is per-token label for the input (source), which corresponds to whether the input token is a grammatical error. This task of tagging each source token with an error label is also called grammatical error detection (GED). Another type of supervision is for per-token labels for the output (hypothesis), which corresponds to whether the output of the GEC system is correct or not.
In the experiments, the authors verify that their proposed model (called VERNet) outperforms BERT-based GED models and neural QE models by Chollampatt and Ng, 2018. Finally, they rerank the hypotheses of a basic GEC model and showed that combining VERTNet-based quality estimation can improve the quality (measured by F0.5) of GEC.
My two cents: the model looks a bit convoluted at first, but it is actually just a bunch of attention and aggregation operations. I think a similar (if not better) model can be formalized as a graph attention network (Veličković et al. 2017) of sources, hypotheses, and tokens.
Learning prerequisite relations from concept graphs
In education, prerequisite relations between concepts play an important role. When you learn machine learning, for example, understanding Conditional Random Field (CRF) requires the understanding of Hidden Markov Model (HMM). In other words, HMM is a prerequisite for understanding CRF. You can leverage such knowledge for designing better curricula and educational applications.
As there is a growing amount of online materials and MOOCs becoming available, extracting prerequisite relations from those materials has been an active research area, since annotating such relations by hand is costly. Common approaches include dependency statistics (Liang et al., 2015 and Gordon et al., 2016) and machine learning (Li et al., 2018).
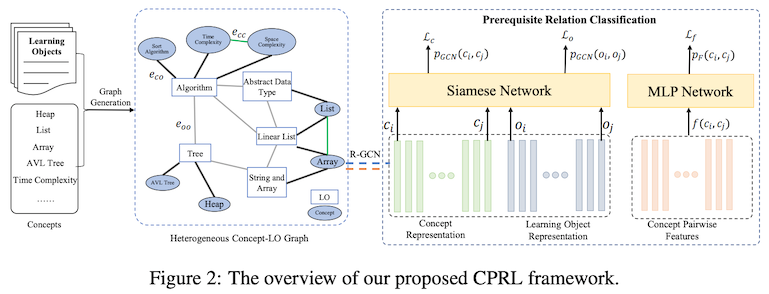
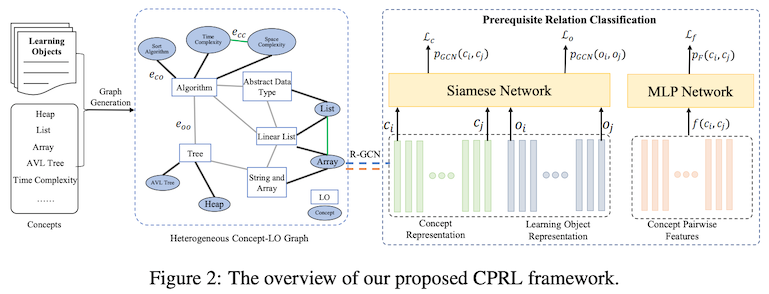
In this paper by Jia and others titled "Heterogeneous Graph Neural Networks for Concept Prerequisite Relation Learning in Educational Data," they built a relational graph convolutional network (R-GCN) to induce the representations for learning objects (e.g., videos in MOOCs, book chapters, etc) and concepts for which we wish to learn prerequisite relations. The graph contains nodes for learning objects and concepts, as well as edges between them based on how they relate to each other. The produced embeddings from this graph are then fed to a Siamese network (twin networks with shared parameters and one classification head) to produce the prediction for whether or not the given concept pair forms a prerequisite relation.
In addition to building a graph neural network, the authors additionally experimented a few techniques for further enhancing the accuracy of relation prediction—in the first technique, they enhanced the training by explicitly learning dependencies between learning objects. In the second, they used a data programming technique Snorkel (Ratner et al., 2017) for generating a large amount of weakly supervised data.
My comments: graph neural networks are a very versatile tool for capturing higher-order, heterogeneous relationship between objects. We applied a similar model to the readability assessment task (Fujinuma and Hagiwara, 2021) and had positive results.
Annotating errors with negative language transfer
Language learners production such as writing is often affected by their first language(s). This is called negative language transfer, and very commonly observed by language teachers and linguists. For example, Chinese speakers who learn English often make article errors since the Chinese language doesn't have corresponding grammar concepts. Knowing whether certain errors are caused by negative language transfer can have several uses, including explicit feedback, which has been shown to increase learners' performance (For example, Shintani and Ellis, 2013).

In this paper by Wanderley et al., the authors built a learner English dataset where errors are accompanied by extra information as to whether it is caused by negative language transfer. As shown in the table above, each error is annotated with a binary flag indicating whether it is due to negative language transfer, and the likely reason for that mistake. The original errors and corrections are based on the FCE Dataset, one of the widely used datasets for grammatical correction.
The authors then moved on to building a model to classify if an error is due to negative transfer. They used a number of linguistic features (dependency, POS tags) as well as the type of the error. They found out that the best performing model was random forest combined with three features—the length of the error (measured in words), the error type, and POS tags of two subsequent words. (My comment: here, the error type is given by humans, so this result may be overestimated compared to real settings where machines need to classify both error types and negative transfer)
Finally, the dataset and the task described here are related to the work by Nagata (2019) (whom I personally collaborate with). He proposed the "feedback comment generation" task and built a dataset for explicit grammatical feedback for language learners. The authors note that these datasets may be complementary. Also, the same authors reported a similar work (Wanderley and Epp, 2021) earlier this year at BEA 2021.
Spanish Writing Mentor
There's a wide array of writing support tools that help students write better in English, including Grammarly, Ginger, and Writing Mentor. In contrast, other languages do not receive that much attention in terms of writing support, including Spanish. In this NAACL 2021 demo paper by Cahill et al. (from ETS) they built Spanish Writing Mentor, basically a Spanish version of Writing Mentor.
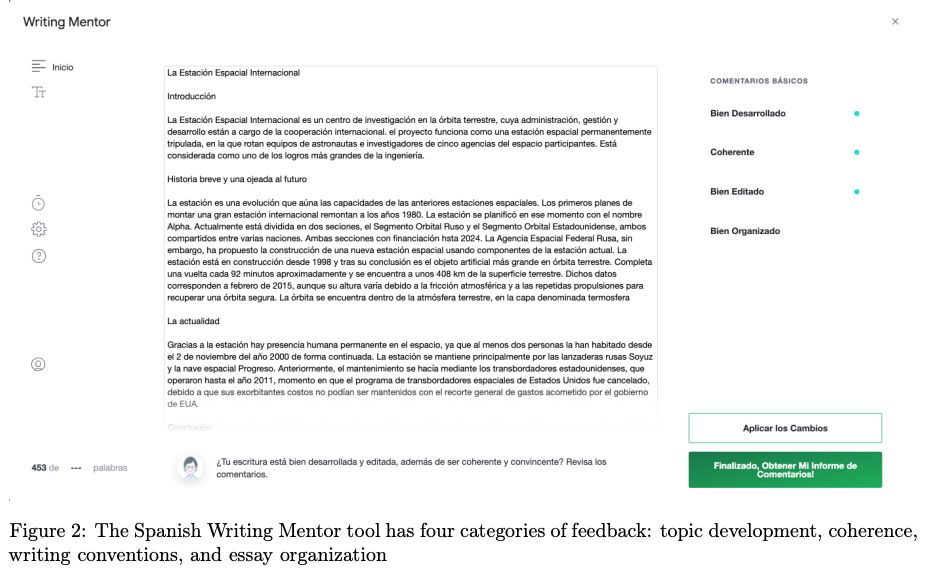
The tool works as a freely available Google Doc add-on with a server-side backend. It has several feedback components that show you different aspects of writing feedback:
- Topic development—they used PMI (pointwise mutual information)-based co-occurrence analysis and identified topic words for helping topic development
- Coherence—this component highlights linguistic units that are related to coherence, including topic words, transition terms (such as because/first/in conclusion, etc.), title and section headers, sentence/paragraph length, and pronoun use.
- Writing conventions—this falls within more conventional writing support, including: grammar, usage, mechanics, unnecessary words, contractions, and accents. For grammatical error detection/correction, they used a subset of error types detected by LanguageTool, an open-source grammar checker that supports multiple languages.
- Essay organization—the tool shows a set of questions that prompt the user to think about the organization of their essay (Note that this is not an automated feature)
In the user study, they recruited a total of university 13 students who are enrolled in the writing courses. They used the tool to support their regular course assignments. They took the standardized test for assessing writing ability before and after the tool use, and the authors observed an increase in their average scores (although one is not sure if the increase is attributed to the tool use since this is not a randomized controlled trial)
According to the user study, the students liked the features related to coherence, organization, and topic development the best. A small number of users kept using the tool even after the user study was finished.
My comments: As an avid language learner, it is refreshing to see writing tools supporting many languages besides English. When we published TEASPN one of the most frequently asked questions was "when is it going to support other languages?" I would have liked to see more than just "we ported the tool from English to Spanish and it also worked" from this paper, though. I expect that as we move onto more low-resource languages, the available open-source tools and datasets become scarcer, and it becomes more challenging to build a writing support tool that can give accurate and comprehensive feedback.