

It's been a while since the "deep learning wave" has reached the field of NLP. Deep models also made a profound impact on how we preprocess texts. Since neural networks often need to operate on a smaller, restricted set of vocabulary items, practitioners have come up with a number of methods that break the input text into subwords. In this article, we'll cover several subword tokenization techniques and software. Oftentimes, these methods are called by a blanked term "subword tokenization," but understanding how they work and their differences will help you better design your NLP models.
How to deal with rare words
In NLP, the input text goes through a process called tokenization, which breaks it into tokens (atomic unit of processing such as words and punctuations). For example, a sentence "The basket was filled with strawberries." can be tokenized as:
The / basket / was / filled / with / strawberries / .
by splitting at whitespaces and punctuations. The set of unique tokens that an NLP system operates on is called a vocabulary.
When you feed the input text into a neural model, you usually tokenize the input and convert tokens into integer IDs, which are then used to look up the embeddings in a mapping table. If an input token is not in the vocabulary, its ID cannot be looked up. Such tokens are called out-of-vocabulary, or OOV, tokens.
A vocabulary is usually a set of words that appear frequently in a corpus, and low frequency words are more likely to be out of vocabulary. Traditional NLP applications operate on a fixed vocabulary and collapsed any tokens that are outside of it into a special token "UNK" (unknown). For example, if the word "strawberries" is OOV in the example above, the sentence will be represented as:
The / basket / was / filled / with / UNK / .
However, collapsing all low frequency words into UNK is obviously not ideal—in this example, you wouldn't be able to know that "strawberries" is a type of berries, for example.
One (rather radical) solution to this is to give up on tokenizing altogether, and split everything into individual characters:
T / h / e / _ / b / a / s / k / e / t / _ / w / a / s / ...
There would hardly ever be unknown tokens this way, because your "vocabulary" now consists of individual characters (in English, all uppercase and lowercase alphabets, as well as numbers and some punctuations). In fact, character-based tokenization is a decent approach for e.g., translating Chinese, a language where individual characters do convey some meaning.
A downside of this is computational cost—splitting everything up into individual characters makes sequences long, which leads to increased memory footage and computation time. If you are using a (vanilla) Transformer model, whose cost increases quadratically $O(n^2)$ with respect to the input length $n$, this becomes an issue.
Could there be the best of both worlds? For example, can we tokenize high frequency words like "the" as whole words, whereas further split low frequency words like "strawberries" into smaller units, i.e., "straw" + "berries"? This is basically what subword tokenization methods do. Let's see them in detail below.
WordPiece — the original subword model
The 2012 paper by Schuster and Nakajima proposes the "original" a model called "WordPieceModel." As far as I'm aware, this is the first and original subword tokenization model. As you can see from its title, the paper is about voice search in Japanese and Korean, although the it's often cited for its contribution to the subword tokenization algorithm.
As mentioned above, an "ideal" subword tokenizer keeps high frequency words such as English "the" and "us" as whole words, while splitting low frequency and/or morphologically complex words (e.g., German nouns) into smaller units. WordPieceModel uses the following algorithm to tokenize subwords from raw text:
- Initialize the first vocabulary by collecting unique Unicode characters from the training text
- Build a language model from the training text with the vocabulary set made in 1
- Choose two vocabulary items out of the current vocabulary set, merge them, and add the new unit back to the set. Merging units are chosen so that it increases the likelihood the training set the most.
- Repeat this until the vocabulary set reaches a predefined size or the likelihood stops increasing
This algorithm would merge frequent units in early stages while leaving infrequent words as smaller units. This algorithm works deterministically and can tokenize any new input with $O(n)$ cost. You don't need special inference algorithms such as dynamic programming.
WordPieceModel works very similarly to BPE (described below) except how it chooses the units to merge. People often use terms WordPiece and BPE interchangeably, but you need to keep in mind that their algorithms are slightly different.
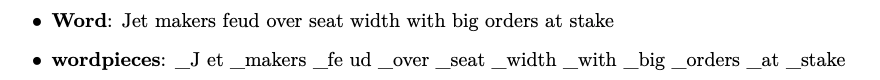
WordPieceModel made a comeback later in 2016 in Google's neural machine translation (GNMT) paper (Wu et al. 2016).
In machine translation, simply "copying" low frequency words such as names verbatim is a decent strategy, especially between languages with shared alphabets such as English and German. It'd be efficient for the model if it operates on the same set of subword vocabulary so that it can tokenize consistently across languages.
In the paper, they show that WordPiece tokenization achieved better translation accuracy than word-based and character-based tokenization.
In addition to GNMT, WordPiece is also used for tokenizing input for BERT (Devlin et al. 2018). However, the BERT tokenizer (see the implementation of the HuggingFace Transformers library for example) splits text greedily based on a BPE vocabulary, which, strictly speaking, is different from WordPiece and BPE.
Byte-pair encoding (BPE) — the king of subword tokenization

Byte-pair encoding (BPE), which as a standard subword tokenization algorithm, has been proposed in Sennrich et al. 2016 almost concurrently with the GNMT paper mentioned above.
They motivate subword tokenization by the fact that human translators translate creatively by composing new words from the translation of its sub-components. For example, the Chinese translation for "neural machine translation", "神经机器翻译", is just a concatenation of individually translated words.
BPE was originally designed as a data compression technique which the paper adapted to word segmentation. The algorithm is almost the same as WordPiece mentioned above. First, the text is split into characters to form the initial set of vocabulary items. Then, a new item AB is formed by merging the most frequent adjacent pair (A, B) in the corpus and added back to the vocabulary. This is repeated until the vocabulary reaches the desired size. In the example above, merges happen in this order: "r + ・ → r・", "l + o → lo", "lo + w → low", and "e + r・ → er・". The special symbol "・" is added to mark the end of each word. The original text can be reconstructed by merging subwords and replacing "・" with whitespace.
Note that BPE tokenization does not cross word boundaries. For example, a subword "e_b" won't be generated from "The basket." Whitespace delimited languages need to be pre-tokenized before being fed to BPE.
In the paper, the authors show that BPE improves BLEU scores as well as word coverage for English-to-Russian and English-to-German translation.
Unigram language models and SentencePiece
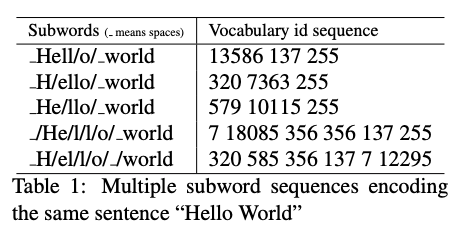
Subword tokenization with an unigram language model first appeared in (Kudo 2018), which proposes a method called "subword regularization," a regularization technique for machine translation.
The key idea is that there can be multiple ways to tokenize a single text into subwords, even with the same vocabulary. In the figure above, for example, "Hello world" is segmented into subwords. You see that the result differs significantly depending on the split positions and orders. The difference is more salient if you convert them into a list of vocabulary IDs. These different segmentation results look completely different from the machine translation model. You can exploit these ambiguities and expose the model to many diverse segmentation results during the training as a form of regularization.
However, since BPE operates greedily by combining frequent character pairs, it is not straightforward to "sample" subword units stochastically. That is, it can't model $ P(\mathbf{x}|X) $ in a straightforward way, where $X$ is the input and $\mathbf{x}$ is the tokenization result.
Kudo proposes a tokenization method based on a subword unigram language model, where segmentation is sampled from
$$ P(\mathbf{x}) = \prod_{i=1}^M p(x_i) $$
If you want to tokenize deterministically, the subword sequence that maximizes this probability can be derived with a Viterbi algorithm. You can also perform k-best with the Forward-DP Backward-A* algorithm. If you sample from this probability during training, the model will be exposed to diverse tokenization, which is a type of data augmentation. This unigram LM tokenization is backed by a probabilistic model, which is the biggest difference from BPE.
You can think of this as performing some sort of compression by minimizing the total code length of the text. In whitespace-delimited languages such as English, texts are pretokenized and subword units that do not cross word boundaries are usually used. On the other hand, in languages such as Japanese and Chinese, subwords are extracted from unsegmented texts without pretokenization.
In Kudo's experiments, he showed that subword regularization improved BLEU scores in most language pairs, especially for low-resource languages.

This unigram LM segmentation is implemented in SentencePiece, an open source segmentation library that I suspect some of you have used before.
One thing to note is that SentencePiece is the name of a software tool which implements both unigram LM segmentation and BPE. However, it is usually used to train/run the unigram LM segmentation and the name is often used interchangeably in practice.
The technical details of SentencePiece is in (Kudo and Richardson 2018). They pay special attention to detokenization, which is a reverse operation of tokenization (going back from "Hello / world / ." to "Hello world."). In languages such as English, this appears trivial—you simply concatenate tokens back with whitespaces in between. However, in order to reconstruct "Hello world." you need to remember to insert whitespace between words while not inserting whitespace before punctuations. There are many other considerations—how about double quotation marks? Apostrophes? etc. These language-specific rules can be very complex. SentencePiece, on the other hand, escape whitespaces and treat them as a regular alphabet, which simplifies things and makes it easy to de-tokenize in a language independent manner.
As I wrote above, languages like Japanese and Chinese are not pretokenized. In their machine translation experiment, not pretokenizing lead to higher performance, especially when the target language is Japanese.
SentencePiece is used to tokenize input for XLNet (Yang et al. 2019) and mBART (Liu et al. 2020).
BPE-dropout — regularization method with BPE
I mentioned above that BPE is not based on a probabilistic and you cannot stochastically sample tokens out of it, which is not entirely correct.
BPE dropout (Provilkov et al. 2020), proposed at ACL 2020, is a regularization method that tokenizes the input text with BPE in a nondeterministic way.

BPE-dropout enables this by modifying the algorithm of BPE slightly. Specifically, when BPE merges two consecutive units, possible merge operations are removed (or dropped) with a small (e.g., $p = 0.1$) probability. If you do this during model training, you can achieve the same effect as the subword regularization mentioned above. At the inference time, you can apply the regular BPE algorithm without dropping merges to get deterministic results.
BPE-dropout can use the same vocabulary and the segmentation algorithm almost as-is, and doesn't require special training or inference procedure, which the unigram LM tokenization does. The experiments showed that BPE-dropout improved machine translation results, by a larger margin than the other method.
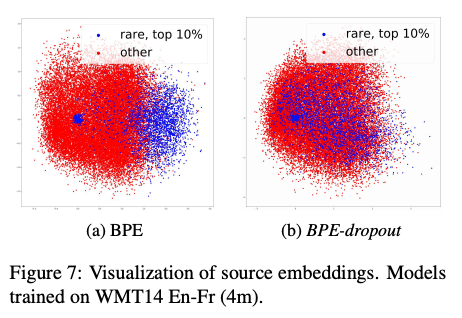
The paper also shows qualitative analyses into the results. By visualizing the embeddings learned by BPE-dropout, the authors show that their model alleviate the problem where low frequency words tend to cluster together (see the figure above) and they were able to train a model robust to misspelled input.
BPE-dropout is also used in the system (Chronopoulou et al. 2020) which ranked #1 at the WMT 2020 unsupervised machine translation shared task. They report that BPE-dropout helped train a more robust system for low-resource languages.
Dynamic programming encoding (DPE) — training the optimal segmentation
Finally, I'll briefly touch upon a recent model proposed by (He et al. 2020) called dynamic programming encoding, or DPE.
As we've shown above, although there can be multiple ways to segment a single string, tasks such as machine translation do not care how exactly the target sentence is segmented, as long as it produces best results. The key to this method is to treat segmentation as a latent variable and to marginalize it to produce the optimal (in terms of maximal likelihood) results for the task.
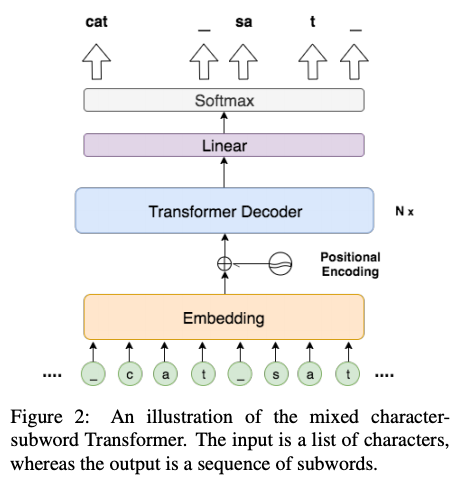
Specifically, we first build a Transformer model that, given the text $x$ as a sequence of characters to an encoder, models the probability $\log p(y | x)$ of subwords $y$ at output positions. This enables one to compute the marginalized probability $ \log p(\mathbf{y}) = \log\sum_{\mathbf{z} \in Z}p(\mathbf{y}, \mathbf{z})$ with dynamic programming considering all possible tokenizations $\mathbf{z}$ for the sentence. Since this marginalization is differentiable, you can optimize it via e.g., regular SGD implemented in PyTorch. The models is trained on the training data (parallel corpus) and the Transformer that produces the best segmentation is obtained. For inference, the optimal segmentation can be computed via a dynamic programming algorithm similar to the Viterbi algorithm.
Note that the trained Transformer model is just to compute segmentation, and is not used for training the MT model. After segmenting the target side with DPE, BPE-dropout is applied to the source side, and a regular MT model is trained. Notice that two different methods are used to segment two sides of the corpus.

In the experiments, they confirmed that DPE improves the translation compared to BPE and BPE-dropout. Also, DPE is shown to lead to more morphologically valid segmentation, as shown in the figure above.
There is a related work in EMNLP 2020 Findings (Hiraoka et al. 2020) where they proposed optimizing segmentation for any downstream tasks.
Conclusion
As of this writing, the mainstream tokenization for neural models can be summarized as "BPE by default, maybe SentencePiece for multilingual." BPE-dropout, which appeared last year, may become more widespread mainly in ML due to its simplicity. As neural models become widespread, tokenization and word segmentation are getting more and more language independent. I welcome this trend—people no longer need to worry about language-specific rules and toolkits in order to train practical systems.
Finally, many methods I introduced here are covered in Mr. Taku Kudo's NLP seminar 2020 presentation (in Japanese). I thank him for the wonderful talk (not archived, unfortunately).