
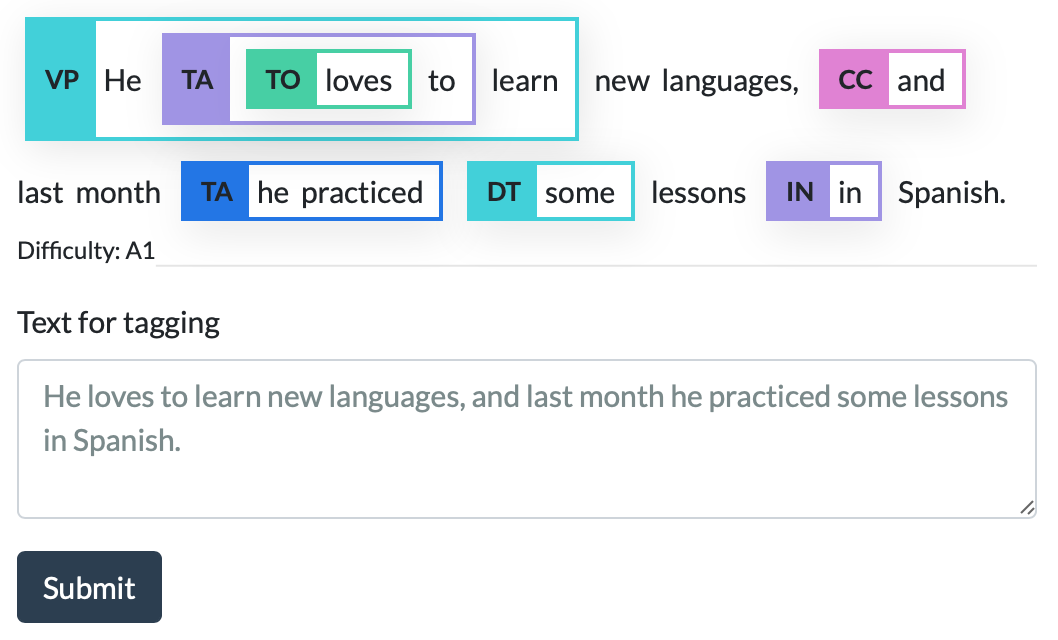
Today we (Octanove Labs) are happy to announce GrammarTagger, an open-source toolkit for grammatical profiling for language learning. It can analyze text in English and Chinese and show you grammatical items included in the input, along with its estimated difficulty.
We open sourced the code (Apache 2.0 license) as well as the pretrained models (CC BY-NC-ND 4.0) on GitHub. In this blog post, I'm going to talk about the motivation for this and how we designed the toolkit and the machine learning model behind it.
Why grammar?
If you are like me and learned a second language at school, you may have gone through a lot of "grammar" learning. When I learned English at school, we would memorize common grammar concepts such as "relative clauses," "second conditional," as well as more rarer ones such as "S+V+O" and "S+V+O+C" structures. Our textbooks were filled with "grammar points" that ranged from lexical items (how to use "the" properly) to morphological rules (third person singular "s"), as well as those structural ones.
Like it or not, grammar plays an important role in language education. As a learner, you may want to identify what grammatical concepts a particular sentence has. As an educator, you may spend some time looking for examples and learning materials suitable for teaching specific grammar. There is past research showing that grammar plays an important role in second language reading assessment (Xia et al. 2016). This is why we think it is important to be able to identify grammatical items from text automatically.
Why not regular expressions?
There have been past efforts to automatically identify those "grammatical items" (or GIs in short) from texts. As you may have imagined, writing simple patterns as regular expressions goes a long way. For example, CEFR-J Grammar Profile defined a couple hundred GIs and analyzed how they are used in textbooks by writing regular expressions against PoS-tagged texts. In order to extract Japanese GIs, Wang and Anderson wrote regular expressions against dependency parsed texts. However, writing such rules requires deep understanding of computational linguistics and the constituency/dependency grammars. This approach is also prone to error propagation—you cannot recover from errors made by the PoS tagger and the upstream parser.
How we solved this
Instead, we drew on recent advance in machine learning and natural language processing, namely, neural network-based representation learning and span classification. We used BERT (Devlin et al. 2019) for encoding the input and each possible span (a substring of the input) is represented as an embedding. Then we use the embedding to classify if the span corresponds to a particular GI, or an empty span (no corresponding GIs). This approach makes the annotation process simple and painless—all you need to do is annotate the start and the end position and its GI tag. It also supports flexible modeling—spans can nest and overlap, and the model can learn from partially annotated data.
It turns out that this span classification approach is very powerful. We were able to build a model that achieves an F measure of around 0.6 with only a couple hundred annotated sentences, both in English and Chinese. For more technical details, please refer to the following paper:
Building a search engine for learning materials
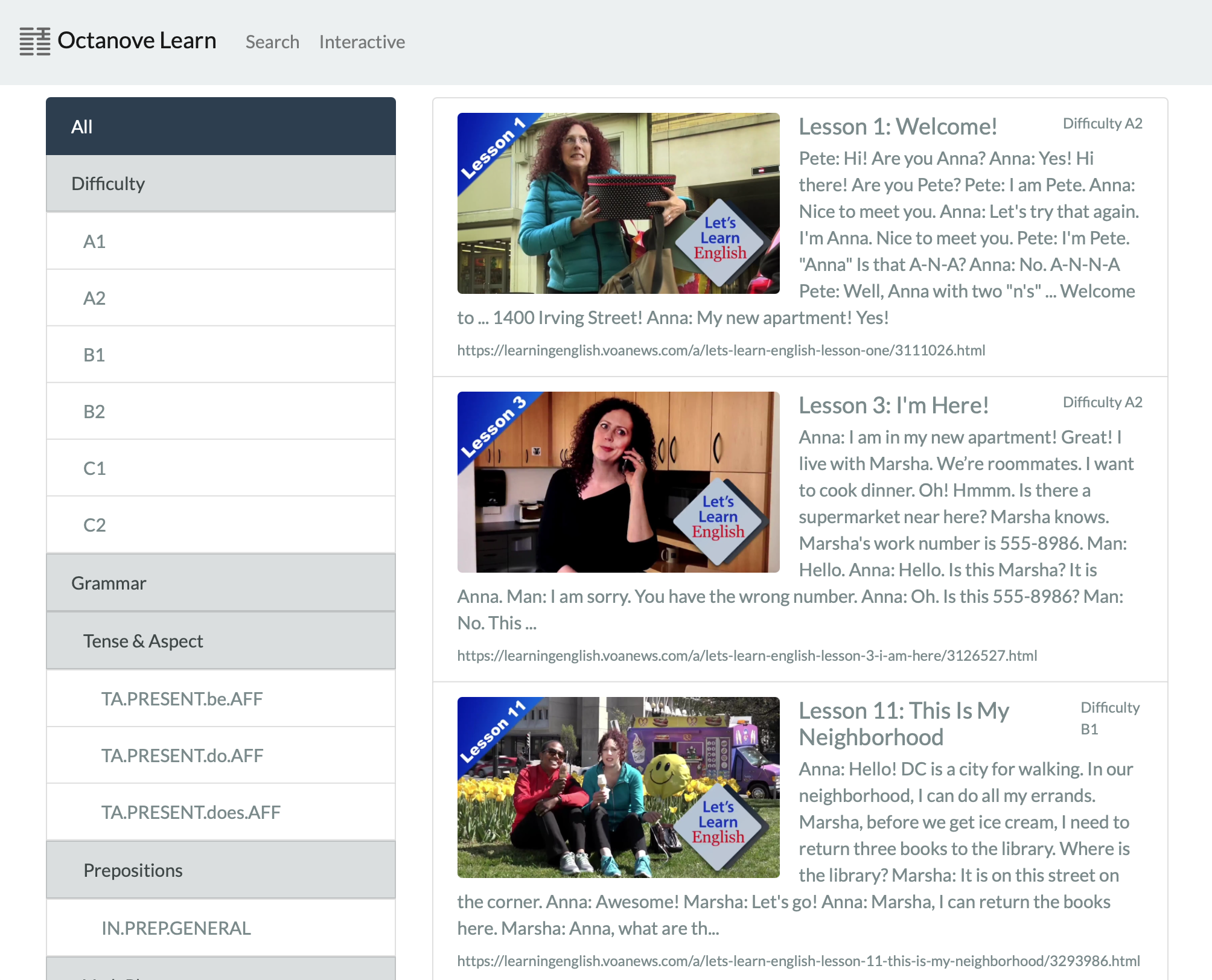
Finally, we are also launching Octanove Learn, a search engine where users can find learning materials by the GIs they include and their difficulty. We currently index public domain materials (VOA Learn English). Language learners and educators can find examples of GIs at specific difficulties. You can also run GrammarTagger via a Web interface.
GrammarTagger is a joint work by Masato Hagiwara (Octanove Labs), Joshua Tanner (University of Washington / University of Tokyo), and Keisuke Sakaguchi (Allen Institute for AI).