
tl;dr
I redesigned Morse code with modern statistical techniques including neural networks, and this is what it sounds like—
NeuralMorse is a research project by Octanove Institute, a distributed AI research lab focused on intelligence augmentation (IA).
Introduction
I love Morse code. The idea of encoding natural language with just two elements always fascinated me since I was a teenager. Even though it may have fallen out of fashion and is not in wide use anymore, the invention strikes as a beautiful combination of information theory and linguistics, and it even has some musical taste to it.

In Morse code, every letter is transmitted as a sequence of just two elements—dots and dashes. It is designed so that natural language text is transmitted as efficiently as possible. The length of each symbol (a sequence of elements) is roughly inversely proportional to the frequency of that letter. For example, the most frequent letter in English, “e” is encoded as just a single dot, while it takes four elements (dash dash dot dash) to encode the less frequent letter “q.”
However, I couldn’t help but think if it could be even more efficient. For example, in English, the word “the” appears a lot more often than the letter “q” does. You’d be able to communicate a lot more efficiently if you dynamically tokenize the text and assign, for example, a shorter symbol to the whole word “the” and a longer one to the letter “q”. Also, if you allowed more than two elements (for example, with different lengths and pitches) instead of just dots and dashes, you’d be able to “compress” a lot more information within unit time.
What if we were to redesign Morse code with modern statistical techniques? That’s how I started designing “NeuralMorse” — a scheme to encode text just like Morse code, but designed with neural networks for higher efficiency.
Desiderata
It’d be tempting to just jump at the problem and start thinking about what we should assign to “the,” for example, but that kind of ad-hoc design would probably go nowhere. Let’s first write out some desirable properties we want it to have, and go from there. We want NeuralMorse to:
- Encode text as sequences of a small number of “alphabets” (just like Morse code, but more elements).
- Encode words as well as characters as symbols.
- Encode English text as efficiently as possible.
- Encode similar words with similar codes.
- Be musically pleasant (if possible).
Elements
How many elements should NeuralMorse use to encode text? Two is not much different from Morse code, while 7 is probably too much. Solresol (a constructed language that uses musical notes to express meaning, one of the inspirations for NeuralMorse) uses 7 different notes of the C major scale, but one criticism of the language is that it'd be too difficult to use for someone without musical training and absolute pitch.
I settled for a total of eight elements with four different “pitches” with two different durations, as follows:
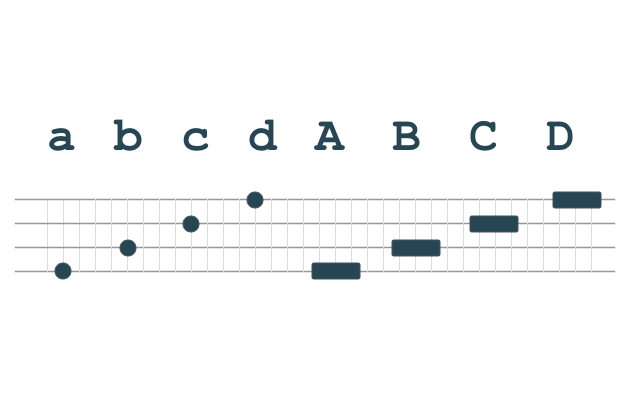
The capitalized elements (A, B, C, D) have the same “pitches” as their lower-case counterparts (a, b, c, d) but three times as long, just like the dots and dashes in Morse code. I think you can distinguish four different pitches spaced appropriately even if you don’t have musical training.
Note that these different elements can be realized as any separate pitches you like, or even via different modalities of communication altogether. For example, they can be encoded as different pitches of sound, or different colors of light, or even different types of smoke. NeuralMorse doesn’t specify how exactly they are realized, as long as they are something that the communicators can encode and decode consistently.
In the rest of the articles and in my implementation, I’ll use four different pitches:
| Element | Pitch |
|---|---|
| a / A | E4 |
| b / B | A4 (= 440 Hz) |
| c / C | B4 |
| d / D | E5 |
This sounds like the A pentatonic scale and I found it musically pleasant (see note 1), but I'm open to suggestions if you find any interesting encoding schemes for these elements.
Symbols
By combining these elements, we can construct symbols like the ones shown below:
| Symbol | Length |
|---|---|
| a | 1 |
| B | 3 |
| aB | 5 |
| dcba | 7 |
| BaC | 9 |
| ... | ... |
Note that, just like Morse code, the interval between elements is equal to one dot and has the same length as a, b, c, and d. Thus the total length of a symbol is equal to the sum of the total length of its elements plus the number of elements minus 1.
If you enumerate all possible symbols of length 9 or shorter that can be made out of these eight elements, there are 1,800 of them, which are partially shown below. Let's call this set of 1,800 symbols as “basic symbols.”
| Symbol | Length |
|---|---|
| a | 1 |
| ... | ... |
| D | 3 |
| aa | 3 |
| ab | 3 |
| ... | ... |
| Aa | 5 |
| ... | ... |
| Dd | 5 |
| aaa | 5 |
| ... | ... |
| aaaa | 7 |
| aaab | 7 |
| ... | ... |
1,800 sounds a lot, but I think you can learn them with enough training. If you think of them as “basic words,” they are roughly in a ballpark of basic vocabulary sets defined for many languages. For example, a typical list of basic English words usually contains 1,000-2,000 words. A typical elementary student in counties where Chinese characters are used (mainly China and Japan) learns 1,000 to 2,000 characters by the time they reach the sixth grade.
Encoding words and characters efficiently
Now, we need to think about how we can encode words and characters efficiently with NeuralMorse. This was probably the easiest part—this is a very typical NLP problem where the goal is to represent text with a shortest sequence of words and characters defined by a dictionary of a fixed size.
For NeuralMorse, I used SentencePiece, a software toolkit for tokenizing natural language text, which is often used as a preprocessing step for neural networks. It trains a statistical model that tokenizes and detokenizes input text in such a way that it minimizes the total length of codes required to encode the text, given a dictionary of a predetermined size. For example, common words such as “the” and “you” are assigned their own tokens, whereas rarer tokens such as “neuroscience” and “serendipity” are broken into smaller units, which are called “sub-word units.”
To achieve this, SentencePiece learns a unigram language model from a large amount of plain text, usually collected from large text datasets such as web crawls and Wikipedia dumps. After normalizing the input text by lowercasing it, I trained a SentencePiece model with a vocabulary of 1,900 unique tokens (see note 2) using the OpenWebText2 corpus (more precisely, 1/100th sample of the corpus, see note 3).
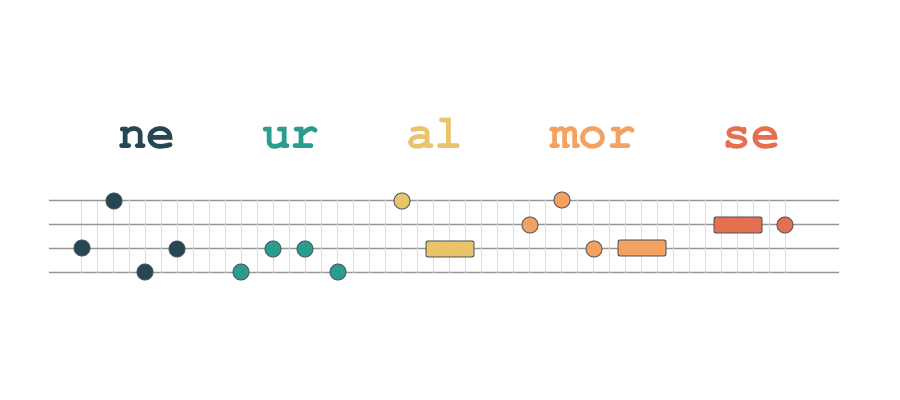
As an example, the model tokenizes a sentence “NeuralMorse is a method for encoding natural language text as sequences of eight tonal alphabets” as follows (“▁” is whitespace):
ne ur al mor se ▁ is ▁ a ▁ method ▁ for ▁ en co ding ▁ natural ▁ language ▁ text ▁ as ▁ s equ ence s ▁ of ▁ eight ▁ to n al ▁ al ph ab et s
Notice that words like “is” “method” “language” become their own tokens, while “neural” “sequence” are broken into sequences of subwords “ne/ur/al” and “s/equ/ence”. The vocabulary has all single letters (a-z) as well as numbers (0-9) and various punctuations (. , ! ? etc.), you can always fall back to single letters even if the input text has some unknown words in it.
Making words with similar meanings sound similar
At this point, we could simply assign each of the 1,800 basic symbols we generated above to each unique token we learned via SentencePiece in such a way that high frequency tokens are assigned to shorter symbols. However, simply doing so purely based on frequency would create assignment between symbols and tokens that are seemingly random, as below:
natural bDac
october Abcd
government Cdac
american dDcd
etc.
Such random assignment might be fine—after all, the assignment between letters and symbols in the original Morse code sounds pretty random. However, trying to memorize 1,800 randomly paired symbols and tokens seems like a very difficult feat. Also, since there are so many symbols that have the same length—for example, symbols of the form Aaaa, aAaa, AAa, etc., are all 9 dot long, and there are 1,216 of them. We need some ways to break the tie between these symbols.
In many natural languages, there is some correlation between what words mean and how words sound—for example, all adjectives in Japanese end with “-i” and in Esperanto with “-a.” Even in English, morphological rules such as “recent” vs “recently” and “success” vs “successful” make it a lot easier to remember all these words, even though they are technically distinct words. Therefore, in terms of the learning cost and experience of NeuralMorse, it’d probably be better if related words sound somewhat similar (i.e. they are assigned similar symbols).
How can we achieve this? This is where the neural network comes into play. I trained word embeddings (real-valued vector representations of what they mean) for all the tokens we learned via SentencePiece, for using them as references when assigning symbols to tokens. We trained a SkipGram model using fasttext on a larger corpus (a 1/10th sample of OpenWebText2, which has approximately 2.5 billion words) and ran agglomerative clustering to learn a dendrogram, which we then converted to binary sequences representing how words are branched from the root. By sorting tokens by those binary codes, we get this beautiful list of tokens sorted and arranged by their meanings:
| Token | Code |
|---|---|
| nothing | 000100000 |
| something | 0001000010 |
| anything | 0001000011 |
| someone | 0001000100 |
| anyone | 0001000101 |
| everything | 0001000110 |
| everyone | 0001000111 |
| ... | ... |
| february | 10110111011 |
| april | 1011011110 |
| june | 1011011111 |
| 2020 | 1011100 |
| 2021 | 1011101 |
| 2019 | 10111100 |
| ... | ... |
| york | 11101001100 |
| washington | 11101001101 |
| ville | 11101001110 |
| california | 111010011110 |
| texas | 1110100111110 |
| florida | 1110100111111 |
| ... | ... |
You can also represent any symbols by binary codes by converting elements (a = 000, b = 001, …, D = 111) and concatenating them.
| Symbol | Code |
|---|---|
| ac | 000010 |
| cc | 010010 |
| C | 110 |
| cab | 010000001 |
| bcc | 001010010 |
| Cb | 110001 |
| ... | ... |
| Db | 111001 |
| add | 000011011 |
| dbd | 011001011 |
| cdba | 010011001000 |
| cbbc | 010001001010 |
| ddcd | 011011010011 |
| ... | ... |
Now you can measure the distance between any symbols and tokens by comparing corresponding codes and counting the number of different digits starting from the first one.
Putting all together
Finally, how can we assign symbols to tokens so that 1) frequent tokens get assigned to shorter symbols and 2) tokens with similar embeddings get assigned to similar symbols? Notice that you cannot satisfy these two conflicting goals perfectly—prioritizing the first may lead to more “random” assignment between similar words, while prioritizing the second may lead to less optimal assignment in terms of the length of the encoded text. We want to strike a good balance between the two.
Specifically, for token $t$ and its corresponding symbol $s$, we’d like to minimize the following cost function:
$$
\sum_{(t, s)} c(t, s) = \sum_{(t, s)} dist(code(t), code(s)) + \alpha * freq(t) * len(s)
$$
- $code(t), code(s)$ are the binary code we generated above for token $t$ and symbol $s$
- $dist()$ is the Hamming distance between two codes
- $freq(t)$ is the normalized frequency of token $t$
- $len(s)$ is the length (measured by the number of dots) of symbol $s$
- $\alpha$ is a coefficient that balances the two terms (we set this so that the both terms are roughly in the same range)
The first term corresponds to condition 2 while the second corresponds to 1. Now, all we need to do is find the assignment between symbols and tokens that minimizes the cost function above overall. This is a typical assignment problem that can be solved efficiently. I simply created a cost matrix filled with $c(t, s)$ for all possible combinations of $t$ and $s$, and solved the problem with scipy. Here’s some excerpt from the assignment:
| Token | Symbol |
|---|---|
| have | bda |
| has | ada |
| had | bdad |
| become | bdBa |
| became | bdBc |
| went | bdbA |
| saw | bdBb |
| are | bdb |
| were | bdac |
| was | bD |
| is | bd |
| 's | bcb |
| taken | bdCa |
| took | bdaA |
| take | bdcc |
| taking | bdaD |
| bring | bdDa |
| brought | bdDb |
| came | bdDc |
| come | bddd |
| ... | ... |
Also here's the list of shortest symbols (3 dots or shorter) and assigned tokens:
| Token | Symbol |
|---|---|
| the | a |
| . | b |
| s | c |
| , | d |
| i | A |
| c | B |
| re | C |
| y | D |
| " | aa |
| t | ab |
| that | ac |
| it | ad |
| to | ba |
| d | bb |
| a | bc |
| is | bd |
| - | ca |
| ing | cb |
| and | cc |
| of | cd |
| ed | da |
| on | db |
| for | dc |
| in | dd |
Notice that similar words (e.g., “become” and “became”) have similar symbols (“bdBa” and “bdBc”) assigned, while more frequent words (e.g., “is” and “was”) have shorter symbols (“bd” and “bD”) assigned. Here’s the full list of all the tokens and symbols for NeuralMorse.
NeuralMorse in Action
You can generate and listen to NeuralMorse for any text using this Google Colab notebook. Also, the data and the code needed for inference are found in this repository. I'll upload the scripts that I used training later.
Discussion
I think the most important question here is whether humans can learn to decode NeuralMorse with naked ears after training. If you listen to the encoded text for the first time, it sounds like a random sequence of musical notes and it seems like a very difficult endeavour to learn to decode NeuralMorse in real time.
However, I’ve listened to a bunch of sentences for a while and it started to make some sense, partially because you start to remember some frequent patterns (“the” “you” “-s” etc.). This experience is very similar to when you have just started learning a new language, but dramatically faster. Designing effective training materials for NeuralMorse (something like Google’s Morse Typing Trainer) is definitely an interesting and important next step.
Also, the way I designed NeuralMorse is highly specific to English. I think we can use the same set of techniques for designing similar encoding methods for other languages. Even more interesting is to design a multilingual version of this, where words with similar meanings sound similar regardless of their languages.
Notice that the framework I presented here (statistical tokenization and assignment) is not specific to Morse code or even sound. You can use the same techniques for “re-inventing” some other ways to encode text. For example, it’d be interesting and even practical to redesign Braille with symbols of variable lengths. We’ll leave this to future work.
Notes
-
Note 1: This scale happens to be the same as the basic tuning of Pipa, a Chinese traditional musical instrument that my wife is learning. These elements can be any notes as long as they are separable by human ears—you can probably assign them to four different notes of a chord (e.g., Dm7, G7, Cmaj7 etc.) and change them dynamically to make it sound more like music.
-
Note 2: I used 1,900 unique tokens instead of 1,800 unique tokens to account for extra tokens that start with “_” (whitespace) generated by SentencePiece. As a post-processing step, I force-tokenize whitespace, reducing the vocabulary size by ~100.
-
Note 3: I realized there's a serious bias problem after just learning on the 1/100th of OpenWebText2. Specifically, 1) since OpenWebText2 contains only textual data up to early 2020, it tends to underrepresent relatively new words such as “biden” and “2021”. I collected some extra amount of web pages that are ranked high on the Reddit front page in 2021 to mitigate this. Moreover, 2) the SentencePiece model trained on the OpenWebText2 is not fair to women—I found that a lot of female first names and female specific words (e.g., sister, wife, daughter) were missing from the original dictionary. This means that female names and words would need more symbols to encode by NeuralMorse. When training the SentencePiece model, I oversampled sentences that have words like “she” “her” etc. in the original training corpus, which mitigated this bias to some degree but didn’t solve it completely.