
The progress of the machine learning (ML) and artificial intelligence fields never stopped surprising us this year either. In natural language processing (NLP), new, powerful models such as GPT-3 and T5 are published one after another. The Transformer found its way into the computer vision (CV) field as well (Chen et al. 2020, Dosovitskiy et al. 2020). The exponential growth trend of the number of papers published on arXiv and at conferences hasn't slowed down yet.
In this post, I'm going to use NLP techniques to analyze all the ML/NLP/CV papers published on arXiv this year and summarize the "most frequently mentioned ML topics in 2020." These top-ranked keywords represent the ML trends in 2020 very well, and knowing them in advance will make your job easier when it comes to reading more scientific articles (this is very important for non-native English speakers like me!)
Specifically, I collected the titles and abstracts of all the papers published on arXiv in 2020 via the arXiv API, and extracted named entities with a model trained on SciREX. The SciREX model can extract typed named entities such as tasks, metrics, datasets, and methods, which enables us to rank the mentions per type. The technical details of the analyses are shown in the "technical details" section at the bottom of this article.
Most Frequently Mentioned Topics in 2020 (per Type)
I only focus on the three AI fields—general machine learning (cs.LG), natural language processing (cs.CL), and computer vision (cs.CV). I'm aware that there are many other AI/ML categories on arXiv, although I limited to just three to simplify things.
Machine Learning (cs.LG)
First, let's look at the most mentioned topics in machine learning per type below:
| Datasets | Metrics | Tasks | Methods |
|---|---|---|---|
| CIFER-10 | accuracy | classification | neural network |
| ImageNet | robustness | machine learning | deep neural network |
| MNIST | complexity | training | convolutioal neural network |
| COVID-19 | convergence | learning | deep learning |
| CIFER-100 | computational cost | generalization | machine learning |
| SVHN | classification accuracy | prediction | reinforcement learning |
| chest x-ray | computational complexity | inference | GAN |
| COCO | precision | NLP | machine learning models |
| KITTI | f1 score | reinforcement learning | graph neural network |
| sample complexity | artificial intelligence | classifier |
If you look at the list of datasets, most of them are related to computer vision, which is arguably the most actively researched area in machine learning.
As for the methods, you see neural networks everywhere. Among generic methods such as "neural network" and "deep learning" you also see "graph neural network," which is one of the biggest recent trends in ML.
Machine Learning (cs.LG)
First, let's look at the most mentioned topics in machine learning per type below:
| Datasets | Metrics | Tasks | Methods |
|---|---|---|---|
| CIFER-10 | accuracy | classification | neural network |
| ImageNet | robustness | machine learning | deep neural network |
| MNIST | complexity | training | convolutioal neural network |
| COVID-19 | convergence | learning | deep learning |
| CIFER-100 | computational cost | generalization | machine learning |
| SVHN | classification accuracy | prediction | reinforcement learning |
| chest x-ray | computational complexity | inference | GAN |
| COCO | precision | NLP | machine learning models |
| KITTI | f1 score | reinforcement learning | graph neural network |
| sample complexity | artificial intelligence | classifier |
If you look at the list of datasets, most of them are related to computer vision, which is arguably the most actively researched area in machine learning.
As for the methods, you see neural networks everywhere. Among generic methods such as "neural network" and "deep learning" you also see "graph neural network," which is one of the biggest recent trends in ML.
Natural Language Processing (cs.CL)
Next, the most mentioned topics in NLP are shown below:
| Datasets | Metrics | Tasks | Methods |
|---|---|---|---|
| COVID-19 | accuracy | NLP | BERT |
| English | F1 score | machine translation | language model |
| bleu score | question answering | transformer | |
| Wikipedia | robustness | named entity recognition | LSTM |
| GLUE | word error rate | automatic speech recognition | neural network |
| German | quality | neural machine translation | deep neural network |
| SQuAD | precision | downstream tasks | NLP |
| LibriSpeech | recall | classification | recurrent neural network |
| Wikidata | translation quality | sentiment analysis | neural models |
| Hindi | evaluation metrics | generation | convolutional neural network |
This was obvious in retrospect, but the most mentioned topic in NLP was "COVID-19." A dataset of COVID-related papers CORD-19 was published. An information extraction shared task was held at the W-NUT 2020 workshop. A lot of research efforts were made for analyzing COVID-related information on social media as well as on clinical text. It is also nice to see many authors name the language(s) they work on in the abstract.
Top-mentioned methods are all related to BERT, language models, and transformers. I wonder when the "ImageNet Moment" with transformer-based transfer learning is going to peak out in NLP.
Computer Vision (cs.CV)
Finally, here's the list of most mentioned topics in computer vision.
| Datasets | Metrics | Tasks | Methods |
|---|---|---|---|
| ImageNet | accuracy | segmentation | convolutional neural network |
| CIFER-10 | robustness | classification | deep neural network |
| COCO | classification accuracy | computer vision | deep learning |
| KITTI | precision | object detection | neural network |
| CIFER-100 | computational cost | detection | GAN |
| COVID-19 | maximum a posteriori | training | deep convolutional neural network |
| MNIST | speed | semantic segmentation | deep learning models |
| Cityscapes | computational complexity | image classification | transfer learning |
| chest x-ray | generalization ability | generalization | classifier |
| RGB images | sensitivity | inference | deep learning methods |
Among the "regulars" such as CIFER-10/100, ImageNet, and MNIST, COVID-19 and chest x-ray are in the most mentioned dataset list. There has been a lot of research work on, for example, diagnosis of COVID-19 from chest x-ray images.
The most mentioned task was (semantic) segmentation, which is an important CV task with a wide range of applications such as autonomous driving and medical image processing.
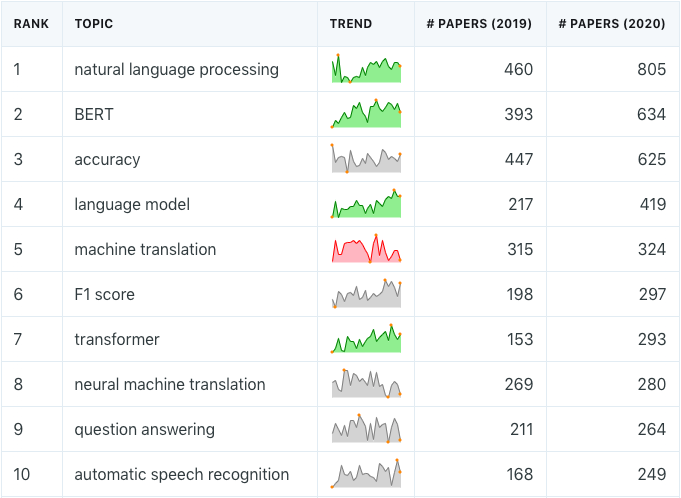
Topics on the Rise in 2020
In the second half of this article, we are going to dive into some trends of individual fields by comparing the number of mentions between 2019 and 2020 and focusing on mentions that have significantly more (or fewer) mentions.
Machine Learning (cs.LG)
First, let's look at the mention trends in machine learning. The following table lists the 20 most mentioned topics in 2020 (regardless of their types) along with their monthly trends (relative number of papers that mention each keyword) in the past 24 months. If a topic has statistically significantly more mentions compared to the expected value based on the 2-year average, the trend is shown in green; red if it's significantly fewer.
| Rank | Topic | Trend | # Papers (2019) | # Papers (2020) |
|---|---|---|---|---|
| 1 | accuracy | 2209 | 2971 | |
| 2 | machine learning | 1503 | 2079 | |
| 3 | neural network | 1530 | 1984 | |
| 4 | deep neural network | 1585 | 1969 | |
| 5 | deep learning | 1174 | 1548 | |
| 6 | convolutional neural network | 1150 | 1296 | |
| 7 | reinforcement learning | 955 | 1204 | |
| 8 | classification | 838 | 1127 | |
| 9 | robustness | 680 | 970 | |
| 10 | training | 635 | 828 | |
| 11 | learning | 650 | 815 | |
| 12 | generalization | 486 | 646 | |
| 13 | generative adversarial network | 601 | 602 | |
| 14 | artificial intelligence | 340 | 568 | |
| 15 | CIFAR-10 | 438 | 560 | |
| 16 | COVID-19 | 1 | 551 | |
| 17 | machine learning models | 365 | 547 | |
| 18 | graph neural network | 230 | 530 | |
| 19 | natural language processing | 307 | 529 | |
| 20 | prediction | 375 | 515 | |
| Total | 19,268 | 25,272 |
Technical Details
I'll describe how I obtained the ranking. The code for the analysis is here.
First, I collected all the paper titles and abstracts in the target categories (cs.LG, cs.CL, cs.CV) published in 2020. All the metadata on arXiv are available under the public domain license. I used arXiv API Python library for fetching the data. The total number of papers analyzed for this post is 83,339.

I then extracted ML-related mentions from collected titles and abstracts. I used the named entity recognition (NER) system trained on SciREX. SciREX is a dataset of scientific papers annotated with mentions (datasets, methods, metrics, and tasks) and their relationship. The official repository has code for training a strong baseline based on SciBERT + CRF, which I used here. Note that SciREX also contains rich annotations such as coreference and N-ary relationship in addition to individual mentions, although I only used their NER model.
Extracted mentions were then normalized (e.g., variants such as cnn, cnn, convolutional neural network, convolutional neural networks) with a handcrafted mapping table. The number of papers that mention each phrase is then counted. I used a chi-square test to determine whether a topic is on the increase/decline.
The "trend" graphs above are visualized using jQuery Sparklines after computing normalized values by dividing the number of papers that mention the topic by the number of total papers published in each month.
If you are interested in the datasets (papers with extracted mentions) I used for this post, download them from the resources page (you need to sign up for free menbership).